
원래는 arena에 대한 설명만 하려 했는데 이 부분이 빠진 것 같아서 끼워넣기를 했다...
heap 영역이 할당되는 과정
기본적으로 malloc 등의 함수를 사용하지 않아도 132KB 크기의 initial heap이 존재한다. 그리고 할당 가능한 요구가 들어오면 heap segment를 확장한다. 여기서 확장하는 것을 sbrk()라고 한다.
start_brk : 프로그램 초기 heap 주소를 나타내는 변수
break location : heap의 끝 주소
brk() : 프로세스의 heap 끝 주소를 설정하는데 사용된다. 프로세스가 런타임 중에 메모리를 필요로 할 때마다 break location을 조정하여 힙의 크기를 증가시키거나 감소시킨다.
sbrk() : brk와 비슷한 역할을 하는데 brk와 차이점으로는 인자값이 상대적인 값으로 받는다는 것이다.
예를 들면
brk(주소 값) 은 주소 값까지 메모리를 할당하고
sbrk(주소 값) 은 주소 값 만큼 메모리를 추가 할당한다.
즉 start_brk 부터 break location 까지가 heap segment이며 brk()(sbrk())를 통해 heap segment를 확장시킨다.

arena
arena란 heap영역 전체를 관리하는 구조체이다. fastbin, smallbin, largebin 등의 정보를 모두 담고 있다. arena는 크게 main arena와 sub arena(main arena가 아닌 arena)로 나뉜다.
main arena
메인 쓰레드로 생성된 것이어서 main_arena이다. 이는 단일 스레드용 프로그램을 위해 존재한다. main_arena는 하나의 heap만 가질 수 있으며 heap_info 구조체를 가질 수 없다. main_arena는 malloc_state구조체를 사용하는 변수이며 이는 top chunk와 비슷하게 공간이 부족하면 더욱 커지고 비어있는 공간이 많으면 줄어들기도 한다. 구조체는 아래와 같다.
static struct malloc_state main_arena =
{
.mutex = _LIBC_LOCK_INITIALIZER,
.next = &main_arena,
.attached_threads = 1
};struct malloc_state
{
/* Serialize access. */
__libc_lock_define (, mutex);
/* Flags (formerly in max_fast). */
int flags;
/* Set if the fastbin chunks contain recently inserted free blocks. */
/* Note this is a bool but not all targets support atomics on booleans. */
int have_fastchunks;
/* Fastbins */
mfastbinptr fastbinsY[NFASTBINS];
/* Base of the topmost chunk -- not otherwise kept in a bin */
mchunkptr top;
/* The remainder from the most recent split of a small request */
mchunkptr last_remainder;
/* Normal bins packed as described above */
mchunkptr bins[NBINS * 2 - 2];
/* Bitmap of bins */
unsigned int binmap[BINMAPSIZE];
/* Linked list */
struct malloc_state *next;
/* Linked list for free arenas. Access to this field is serialized
by free_list_lock in arena.c. */
struct malloc_state *next_free;
/* Number of threads attached to this arena. 0 if the arena is on
the free list. Access to this field is serialized by
free_list_lock in arena.c. */
INTERNAL_SIZE_T attached_threads;
/* Memory allocated from the system in this arena. */
INTERNAL_SIZE_T system_mem;
INTERNAL_SIZE_T max_system_mem;
};

여기서 bins의 첫 번째와 두 번째 는 unsorted bin이고 다음으로 small bin 그다음 large bin이다.
그림으로 보면 편한다.
bins의 구조
기본적으로 bin이 비어있으면 이전 bin의 주소를 가리킨다.
여기서 bin에 chunk가 들어가면 이렇게 된다.
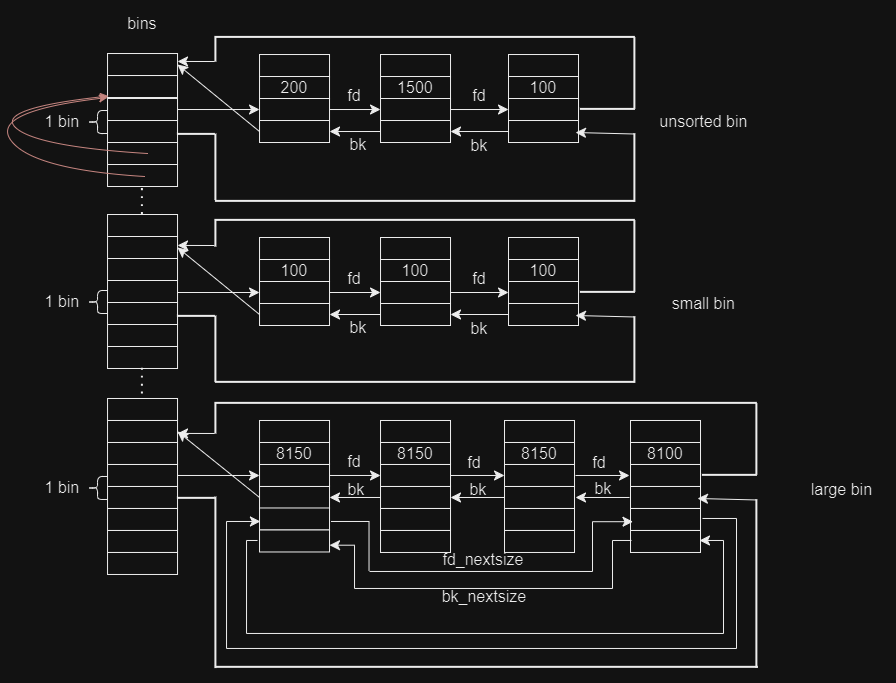
그림상으로는 fd와 bk가 다음 fd, bk를 가리키지만 실제로는 chunk의 주소를 가리키는것이다.
여기서 chunk가 들어올 때는 header의 fd를 참조하여 맨 왼쪽으로 들어오고 chunk가 나갈때는 header의 bk를 참조하여 맨 오른쪽 chunk가 나간다.
단일 연결 리스트인 fast bin은 구조가 살짝 다르다.

마찬가지로 fd는 chunk의 주소를 가리키는 것이다.
chunk가 들어올 때도 왼쪽으로 들어오고 나갈때도 왼쪽에서 나간다.
sub arena
새로운 쓰레드가 생성될 때 다른 스레드를 기다리는 것을 줄이기 위해 새로운 arena를 생성하게 되는데 이를 sub arena라고 부른다. 이는 sbrk()를 사용하는 main arena와 달리 mmap()을 통해 새로운 힙 메모리를 할당받으며 mprotect()를 사용하여 확장한다. 또한 sub arena는 main_arena와 다르게 여러 개의 서브 힙과 heap_info 구조체를 가질 수 있다.

heap_info
heap_info 구조체는 힙의 첫 번째 구조체이다. 이는 힙의 크기를 지정하고 arena의 데이터 구조에 대한 포인터를 제공한다. 이는 멀티쓰레드 환경에서 필요한 것이기에 단일 스레드에서 사용되는 main_arena는 필요 없는 구조체이다.
멀티 쓰레드
일반적으로 단일 arena에서는 모든 스레드가 동일한 arena를 사용한다. 이를 single arena malloc이라 한다.
하지만 멀티 스레드 환경에서는 각 쓰레드마다 별도의 arena를 사용할 수 있다.(모든 스레드가 각자의 arena를 가지는것은 아니다.) 이를 multi arena malloc이라고 한다. multi arena malloc은 각 쓰레드마다 자신만의 arena를 가지고 자신만의 top chunk, free 리스트, 사용 가능한 블록 리스트 등의 것들을 가지고 있다.
ptmalloc은 최대 64개의 arena를 생성할 수 있다. 그래서 과도한 멀티 쓰레드 환경은 병목현상이 발생한다. 그리고 이러한 멀티 쓰레드 환경에서 ptmalloc은 레이스 컨디션을 막기 위해 mutex를 적용한다.
임계영역이란(critical section)?
함수 내에서 둘 이상의 쓰레드가 동시에 실행하면 문제를 일으키는 하나 이상의 코드 블록
Race condition
race condition은 두 개 이상의 쓰레드가 하나의 데이터를 공유할 때 데이터가 동기화되지 않는 상황을 말한다. 이렇게 될 경우 여러 문제가 발생한다.
Mutex(mutual exclusion)
임계영역에 진입할 때 사용하는 잠금장치이다.
작동방식 : mutex를 초기화한 후 임계영역에 mutex lock을 걸어준다. 현재 진입한 스레드 외에 다른 쓰레드는 lock을 건 부분에서 lock이 풀릴때 까지 블로킹 된다. 진입쓰레드가 적업을 마치고 락을 풀고 나가면 기다리던 쓰레드 중 하나가 다시 진입하고 lock을 걸게 된다.
lock() : lock을 걸고 사용권을 얻는다.
unlock() : lock을 해제하고 사용권을 반납한다.
mutex lock은 구현을 잘못하거나 스레드의 수가 과다하게 많아지면 병목현상을 일으킬 수 있다. 락으로 발생하는 대표적인 문제 중 하나가 데드락이다.
Dead-Lock
두 스레드가 서로 상대방의 작업이 끝나기를 계속 기다리는 상태이다.
ex) 쓰레드 1이 a, 쓰레드 2가 b를 lock 한 상태에서 쓰레드 1은 b를, 쓰레드 2는 a를 lock 하기 위해 서로 잠금 해제를 기다리는 상황이다.
Spinlock
임계 구역에 들어가는데 실패했을 때, 가능한 상태가 될 때까지 계속 돌면서 진입을 시도하는 방식으로 구현된 lock이다.
Semaphore
공유된 자원을 한정된 수의 스레드만 접근하도록 막는 것이다. 스레드가 임계영역에 접근할 때 해당 스레드는 semaphore의 count를 감소시키고 종료된 후에는 semaphore의 count를 원래대로 증가시킨다.
<틀린 부분이 있다면 비난과 욕설을 해주세요>
'포너블 > Heap' 카테고리의 다른 글
| free 소스코드 분석(libc 2.23) (0) | 2023.08.16 |
|---|---|
| malloc 소스코드 분석(libc 2.23) (0) | 2023.08.02 |
| heap의 개념-(3) (0) | 2023.07.10 |
| Heap의 개념-(2) (4) | 2023.07.06 |
| Heap의 개념-(1) (1) | 2023.07.03 |